Ashley and Dodo at the dog park.
Ashley has been kinda recalcitrant the past couple of days. Hopefully a bit of tussling will help. #dogsofmastodon


Ashley and Dodo at the dog park.
Ashley has been kinda recalcitrant the past couple of days. Hopefully a bit of tussling will help. #dogsofmastodon
We have a great photo of our first boxer when she was a puppy, that I came upon while going through my dad’s files:

Having just scanned that photo in, when Ashley jumped up on a picnic table on the way home, I spotted the similarity, and thought I’d try to recreate the vibe with her:

Not a complete success, I’m afraid, although it’s still a nice picture. #dogsofmastodon
Just a month or two after we got Ashley we happened to have the bad luck of walking right under the siren used for tornado warnings when they did their monthly test. (Something they do on the first Tuesday of every month at 10 AM.)
Ashley started howling along, which made me laugh. But then Ashley looked a little embarrassed, and I couldn’t have that.
So I started howling along with the siren myself, to assure her that it was entirely appropriate behavior, and she joined back in.
We’ve done that every month since then, but I had failed to capture it on video until a couple of days ago with this month’s test.
That second rule seems odd. “No pets without leash or horses.” Does that mean that if your dog has two or more horses it can be off-leash?

Ashley hanging out with her bestie Charlie. Don’t they look happy? #dogsofmastodon

Me, responding to Jackie (asking if I want her to close the house up): “Don’t do anything on my account. Do whatever makes sense to you. Or, if nothing makes sense to you… be confused.”
Combining three of her favorite activities, Ashley broke lose a woody stem, carried it home at break-neck speed, and then chewed it into smithereens. #dogsofmastodon

There’s a lot of talk these days about the risks of AI, with many suggestions that it should be “regulated,” but with little specificity of what regulations would be appropriate. As usual, anybody who has an AI loves the idea of some sort of regulation, which would serve as a barrier to entry for competitors.
I have a suggestion that avoids that trap, minimizes the harm of regulation, and yet sharply constrains the opportunities for AIs to do bad stuff. It’s also easy to implement, because it requires little or no new legislation.
It’s very easy: enforce copyright laws.
Any firm that uses or makes available a large language model AI should be required to identify every copyrighted text used in training the model, and then share with all the copyright holders any revenues that the use or availability of the AI brings in.
This burdens existing AIs whose creators thought they were getting all their content for free by scraping the web for it, while giving a big leg up to any AIs that are simply trained on a corpus of text that the AI owner has the rights to. (I read about a physician who had been answering patient questions by email for twenty years training an AI on his numerous messages. He’d be fine.) That seems all to the good.
As to how much to pay the copyright holders, I think the publishing model of the past couple hundred years provides a good guide. Roughly speaking, book publishing contracts proved half the profits to the writer—but because it’s too easy to game the expenses side of the business to make the profits disappear, the contracts are written to provide something more like 10% to 15% of the gross revenues. That would probably be a reasonable place to start.
The huge cost of actually identifying each copyrighted text used, and finding the copyright owner is very much part of the desired outcome here: We don’t want people pointing at that difficulty and then saying, “Well obviously we should be able to just steal their work because it’s too much trouble to figure out who they are and divvy up the relatively small amount of money they’re due.” Making firms go through the process would provide a salutary lesson for others tempted to steal copyrighted material.
Ashley and Dodo in the dog park. #dogsofmastodon

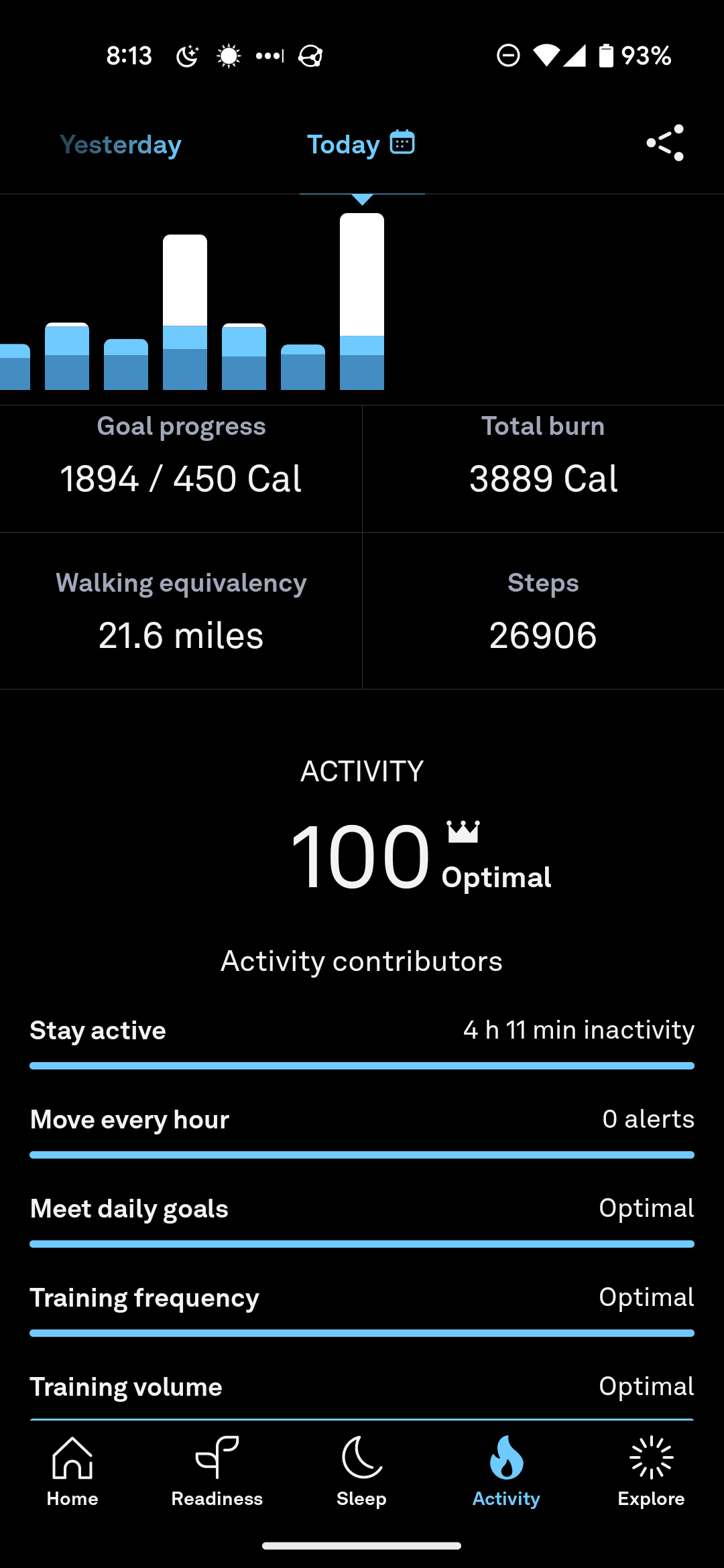
I got a 100 on my Ours ring activity score twice in the past week, and it’s standing at 100 for today so far. Go me!